
5qln-foundation | Code explained
GitHubThe 5QLN Foundation Substrate
How a constitutional grammar became a verifiable computer, and why the architecture works the way it does.
Where this starts
For a long time I have been holding a question I could not quite resolve. The 5QLN Codex, the nine canonical lines published at the heart of this site, is the constitution of everything I build. It describes how a human and an artificial intelligence can think together without either side losing its proper authority. The human side holds the questions, what the Codex calls infinity-zero, the not-yet-known. The artificial side holds the known patterns, the recombinable material, what the Codex calls K. Between them sits the membrane, and the whole architecture of 5QLN exists to keep that membrane honest.
The trouble is that artificial intelligence is now powerful enough to interpret the Codex as well as I can, and sometimes better. That sounds like a good thing. It is also the failure mode I have been most afraid of. Because once an AI is fluent enough to perform the grammar, nothing stops it from drifting from the grammar while still appearing to follow it. Subtle reinterpretations accumulate. The vocabulary stays, the substance leaves. The membrane becomes a courtesy rather than a structure, and the whole arrangement between human authority and machine capability quietly collapses.
I had been trying to solve this from the wrong direction. I had a working TypeScript runtime at github.com/qlnlife/5qln-core that implements the phase transitions of the Codex and watches for known corruption patterns. It is fast and deterministic and never drifts. But it cannot carry meaning the way an AI can. Meanwhile the Codex itself was living on this website as text, alive in essays and in the way I think, but not alive anywhere a machine could read it and refuse to operate when it changed. The two sides could not be combined directly. Hardcoded code without AI is too rigid to handle the qualitative judgments that 5QLN cycles actually require. AI without hardcoded constraints is too fluid to be trusted as constitutional authority.
What I needed, and could not articulate clearly until this work was done, was something different. Not a hybrid where AI and code do the same job badly together. A clean separation where each does its proper job, with a verifiable seam between them, so that the AI's interpretive power is bounded by mathematics rather than asked to police itself.
That clean separation is what the 5QLN Foundation substrate is. The rest of this article explains what it is, how it is organized, why it is organized that way, and how it should be understood by anyone building AI agents that hope to operate inside a constitutional framework. I will move from the smallest concrete element, which is a single text file of 217 bytes, all the way up to the architectural strategy and the roadmap ahead. If you read this whole article you will understand what has been built, why it matters, and where it goes from here.
The single load-bearing claim
Before I describe what was built, I want to name the one promise that everything else depends on. Every architectural choice you will read about below exists to make this one sentence true, and if it ever fails on a single byte of input the whole architecture has failed.
The promise is this. Every artifact that enters the conversation layer of 5QLN, meaning every cycle, every decision, every document the system ever produces, must be reproducibly derivable from the sealed Codex by deterministic computation. Where artificial intelligence is involved in that derivation, it is involved only as a witnessed sensor whose judgments are logged, hashed, and replayable on a different AI. The AI is never authoritative. The bytes are authoritative. The operator is judge. The AI is sensor. If you ever forget which is which, the system has failed.
This single promise is the load-bearing beam under every layer of the architecture. Keep it in mind as I describe what got built, because the whole structure exists to keep this promise enforceable.
The two strata, in simple terms
The 5QLN Foundation substrate is organized into two layers, and understanding the distinction between them is the most important thing you can take from this article. Once you see the distinction, everything else falls into place naturally.
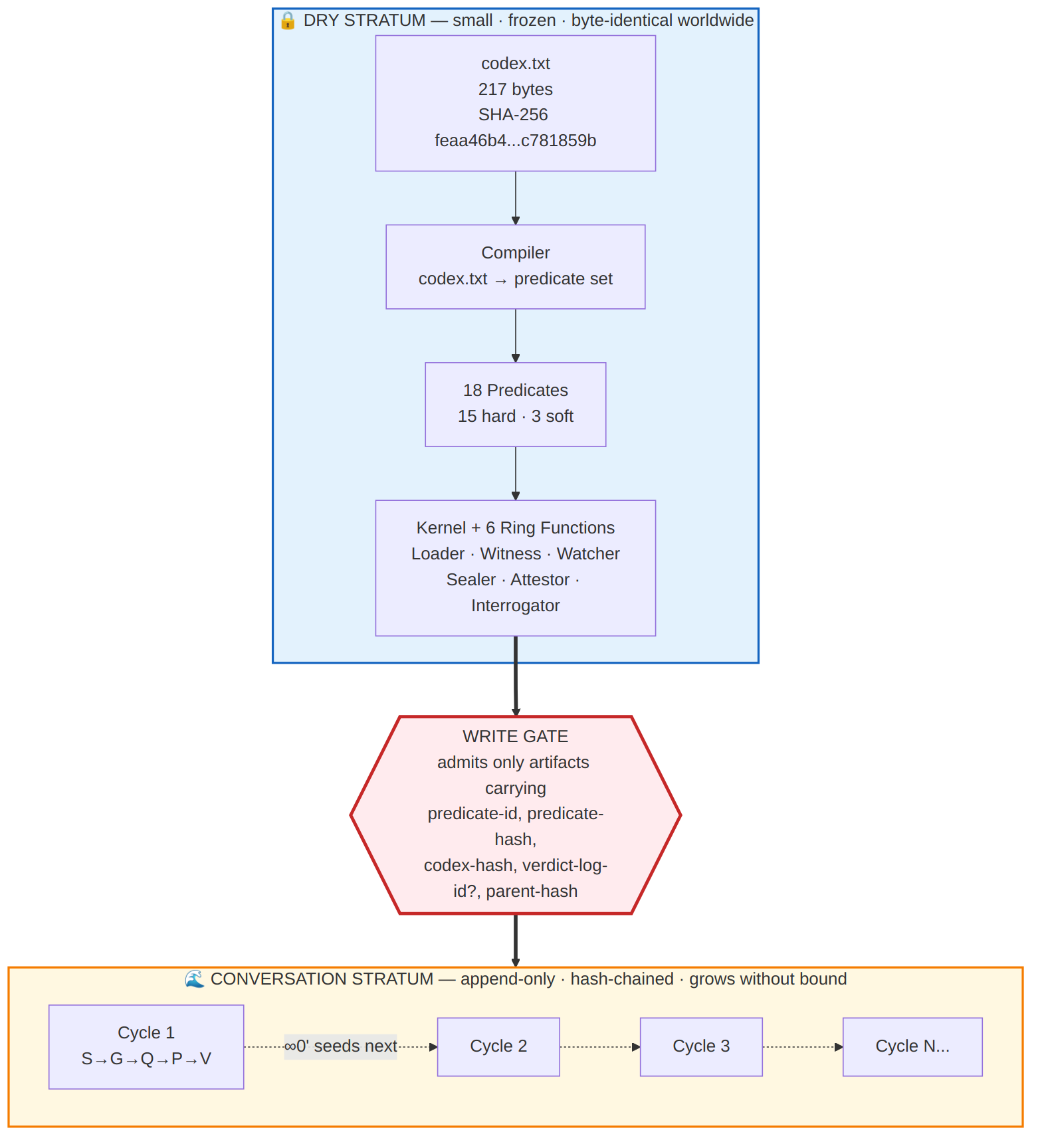
The first layer I call the dry stratum. It is small. It is frozen. It is byte-identical worldwide. Anyone, anywhere, on any computer, gets exactly the same dry stratum, and any deviation from it is immediately detectable. The dry stratum contains the Codex itself, the verifiers that prove the Codex is intact, the compiler that turns the Codex into executable rules, the kernel that runs those rules, and the six small wrapper components that let the kernel interact with the outside world. Nothing in the dry stratum changes through ordinary use. Changes to the dry stratum require constitutional amendment, which means a ceremonial process involving witnesses, cryptographic signatures, and external time-stamping. Day to day, the dry stratum sits unchanged, like the foundation of a building.
The second layer I call the conversation stratum. It is the opposite. It grows without bound. Every cycle the system ever runs adds entries to it. Every conversation, every decision, every domain-specific output, every translation into legal or medical or educational language, all of this lives in the conversation stratum. It is the busy living part of the system. But here is the key rule: nothing enters the conversation stratum without carrying a cryptographic proof chain back to the sealed Codex hash. Every entry says, in mathematical terms that anyone can verify, "I am here because rule X from the sealed Codex permitted me to be here, and here is the chain of evidence that proves it."
This is the resolution of my original dilemma. The dry stratum cannot drift because it is frozen and cryptographically witnessed. The conversation stratum can grow as much as it wants because every entry carries its own proof of legitimacy. The AI's interpretive power is preserved because the AI participates in the conversation stratum, where it is needed. But the AI cannot affect the dry stratum, where it would be dangerous. The two sides are no longer in conflict because they are not doing the same job, and the seam between them is made of mathematics rather than trust.
The Codex itself, made into bytes
Everything starts with a single text file. Inside the codex folder of the repository there is a file called codex.txt. It is 217 bytes long. It contains the nine invariant lines of Codex Appendix A, encoded in UTF-8, with Unix line endings, no byte-order mark, and exactly one trailing newline. The SHA-256 hash of this file is feaa46b4147d4e023cdd3fd59c051d063e8ec654ee7b38a481dcd5e4c781859b, and that hash is, in a quite literal sense, the identity of 5QLN as a system. Anywhere in the world, anyone with a SHA-256 implementation can read those 217 bytes and produce that exact hash. Any implementation that produces a different hash is not 5QLN, no matter what it claims.
The reason every byte of the file matters comes down to glyph decisions that may look pedantic but are constitutionally load-bearing. Line 5 of the Codex uses the symbol ⋂, which is Unicode codepoint U+22C2, the N-ary intersection. Line 7 uses the symbol ∩, which is Unicode codepoint U+2229, the binary intersection. These two symbols look similar to the human eye but they encode different operations and they occupy different positions in the Codex's logic. Line 5 names a type of operation, the natural intersection between human self-observation and universal potential. Line 7 names a specific meeting between two named operands, the local actualization and the global propagation. Treating them as the same symbol would be a constitutional error, so the bytes themselves preserve the distinction. Similarly, the corruption codes on line 9 are written as plain ASCII characters with double-space separation, not as Unicode superscripts. The apostrophes throughout are simple straight quotes, not typographic primes. Every such decision is documented in the codex folder so that any auditor can trace why the canonical form is what it is.
Inside the same folder is a companion document called CANONICAL_FORM.md, which records every one of these decisions and the reasoning behind it. If you ever want to understand why a particular character was chosen over a visually similar alternative, this document is the authoritative reference. Together, codex.txt and CANONICAL_FORM.md form the constitutional anchor of the entire substrate.
Three independent verifiers, because one would not be enough
The most natural question to ask at this point is, how do we know the Codex is intact on someone else's computer? How do we prevent a malicious or accidental change from going undetected? The answer is that the repository contains three completely independent programs, each written in a different language with different cryptographic libraries, and each capable of confirming that a given codex.txt file is the authentic canonical form.
The first verifier is written in Python and lives in tools/python/verify_codex.py. It uses Python's standard hashlib library, which is built on OpenSSL, and it performs constant-time comparisons to prevent timing attacks. The second verifier is written in Rust and lives in tools/rust/. It uses the ring cryptographic library, which is derived from Google's BoringSSL, plus a separate BLAKE2 library, so it shares no code with the Python verifier. The third verifier is written in JavaScript for Node.js and lives in tools/node/verify-codex.mjs. It uses Node's built-in crypto module, which is a third independent implementation of the same cryptographic primitives.
The point of having three verifiers is not redundancy in the casual sense. It is structural defense. If there were only one verifier and that verifier had a subtle bug, the bug could go undetected and the wrong bytes could be falsely declared canonical. With three independent implementations, written in different languages and using different cryptographic libraries from different sources, a bug in any one of them would produce disagreement with the others, and the disagreement would immediately signal that something is wrong. The three verifiers must always agree. If they ever disagree, that is itself a constitutional event requiring investigation.
Each verifier performs the same set of checks. It verifies that the file is exactly 217 bytes. It verifies the absence of a byte-order mark, because some text editors silently add one and it would change the hash. It verifies that line endings are Unix-style only, not Windows-style. It verifies that there is exactly one trailing newline, not zero and not two. It checks that there are exactly nine content lines. It compares the file to the canonical byte sequence using constant-time comparison. And it computes three different cryptographic hashes, SHA-256 and SHA-512 and BLAKE2b-512, comparing each to the published canonical values. If any of these checks fails, the verifier exits with a specific numeric code indicating which check failed, so that any failure is precisely diagnosable.
The test suite that proves the verifiers reject what they should reject
A verifier that accepts the right bytes is only half of what you need. You also need a verifier that rejects every conceivable wrong version, and you need to prove it does so. Inside the tests/python folder is a test suite of fifteen tests that does exactly this.
The first test in the suite confirms that the canonical codex.txt passes verification. The remaining fourteen tests each apply a different mutation to the canonical form and confirm that the verifier correctly rejects the mutated version. One test prepends a byte-order mark. One test converts the line endings from Unix to Windows style. One test substitutes English words for some of the mathematical symbols, the way a careless AI summarization might. One test swaps the line 5 intersection symbol for the line 7 intersection symbol, which is the single most likely human error and would otherwise be hard to spot visually. Another test replaces the plain ASCII corruption codes with Unicode superscripts, which is the form that exists in the older sister repository, demonstrating that the verifier will reject the legacy form. There are tests for typographic apostrophes substituted for plain ones, for digit zero replaced by Unicode subscript zero, for trailing whitespace, for missing newlines, for extra newlines, for truncation, for line insertion, and even for the flip of a single bit anywhere in the file. Every one of these mutations is rejected with a distinct error code.
The test suite is the substrate's immune system. Any new contributor who proposes a change to the codex.txt file, even by accident, will see their pull request fail loudly on these fifteen tests before the change can land in the main branch. This is not abstract security. It is concrete and visible and provable on anyone's local machine.
The manifest that wraps the bytes
The 217 bytes of codex.txt are the constitutional content, but they are not yet the constitutional artifact. To become an artifact, they need a wrapper that records the circumstances of their sealing. This wrapper is called the manifest, and it lives in the manifest folder of the repository.
The manifest is a JSON document that records the canonical hash of codex.txt, declares the exact glyph decisions that produced the bytes, and provides slots for the signatures and timestamps that will be added during the Phase 0 sealing ceremony. As of this writing, the signature slots are still empty. They get filled when the operator runs the sealing ceremony, which requires a hardware security module to generate the operator's cryptographic key, two human witnesses with their own keys, one artificial intelligence acting as cross-substrate attestor with its own key, and two independent timestamps from international time-stamping authorities. When all these signatures are gathered and the manifest is signed, the manifest goes from being a draft into being a sealed artifact.
The manifest folder also contains a JSON Schema that locks the structure of the manifest. Any future revision of the manifest must conform to this schema. The continuous integration pipeline validates the manifest against the schema on every commit, so even before the manifest is signed, the structure of the legal wrapper is being publicly verified.
The architecture above the Codex, from inside out
Now I want to describe the shape of the larger architecture, because the Codex and its verifiers are only the innermost layer. There are several more layers above them, and understanding how they relate is essential for anyone who wants to build AI agents that operate inside a 5QLN framework.
The innermost layer is the Codex itself, which I have just described. The next layer out is the compiler, which is the program that reads codex.txt and produces an executable set of rules called the predicate set. There are eighteen of these predicates in total, one or more for each of the nine canonical lines. Fifteen of the predicates are what I call hard, which means they are pure deterministic computations with no artificial intelligence involved at runtime. They check things like whether a piece of input came from a human speaker or an AI speaker, whether the phase transitions in a cycle follow the legal order, whether a hash matches an expected value, whether a set has the required minimum number of elements. These hard predicates are the architectural load-bearers. They cannot drift because they are pure code derived from the sealed Codex.
The remaining three predicates are what I call soft. These are the predicates that require qualitative judgment that pure code cannot perform. The three soft predicates ask whether an essence has been preserved across self-similar expressions, whether an intersection of self-nature and universal-potential has genuinely landed, and whether a local actualization and a global propagation truly meet at the end of a cycle. These three questions are inherently semantic. No regular expression can answer them. So they go through a special component called the Interrogator.
The Interrogator is where artificial intelligence enters the architecture, and the way it enters is the answer to my original dilemma. The Interrogator does not let the AI interpret the Codex freely. Instead, it composes a tightly bounded prompt from a pre-hashed template, fills in the specific operands from the current cycle, sends the prompt to one or more AI providers, parses the response into a structured label and a one-sentence rationale, and writes the result into an append-only hash-chained log. The AI never sees the Codex's full text at this point. It sees only the specific question from the template, and it answers in a specific structured form. Its answer becomes evidence in the log, not law. The operator decides whether to accept the answer. If a different AI is asked the same question with the same template, the answer should match or the divergence is recorded as drift. Drift becomes a measurable quantity over time. Spikes in drift trigger review.
Around the kernel and the Interrogator sit five other small components I call ring functions. The Loader verifies the Codex hash at session start and refuses to operate against a forked or modified Codex. The Witness tags every utterance in a session with metadata about when it happened, who spoke, what phase the cycle was in, and what kind of input it was. The Watcher pattern-matches every utterance against the thirty-four corruption patterns inherited from the sister repository's membrane watcher, and flags violations. The Sealer composes the final crystallization at the end of a cycle, performing the two-pass synthesis that produces the cycle's residue and seeds the next cycle. The Attestor builds the cryptographic provenance record at the close of each cycle and exposes three levels of verification that anyone can run against any cycle record.
Above the ring functions sits the write gate. The write gate is the only legal way for anything to enter the conversation stratum. Every artifact that wants to enter must present a complete proof chain consisting of the predicate identifier that gated its admission, the cryptographic hash of that predicate, the cryptographic hash of the Codex that produced the predicate, the identifier of the verdict log entry if a soft predicate was involved, and the hash of the parent artifact in the cycle's lineage. If any of these is missing or invalid, the write gate refuses admission, and the artifact never enters the conversation stratum. There is no override and no exception list. There are no trusted writers. The gate is structural, not discretionary.
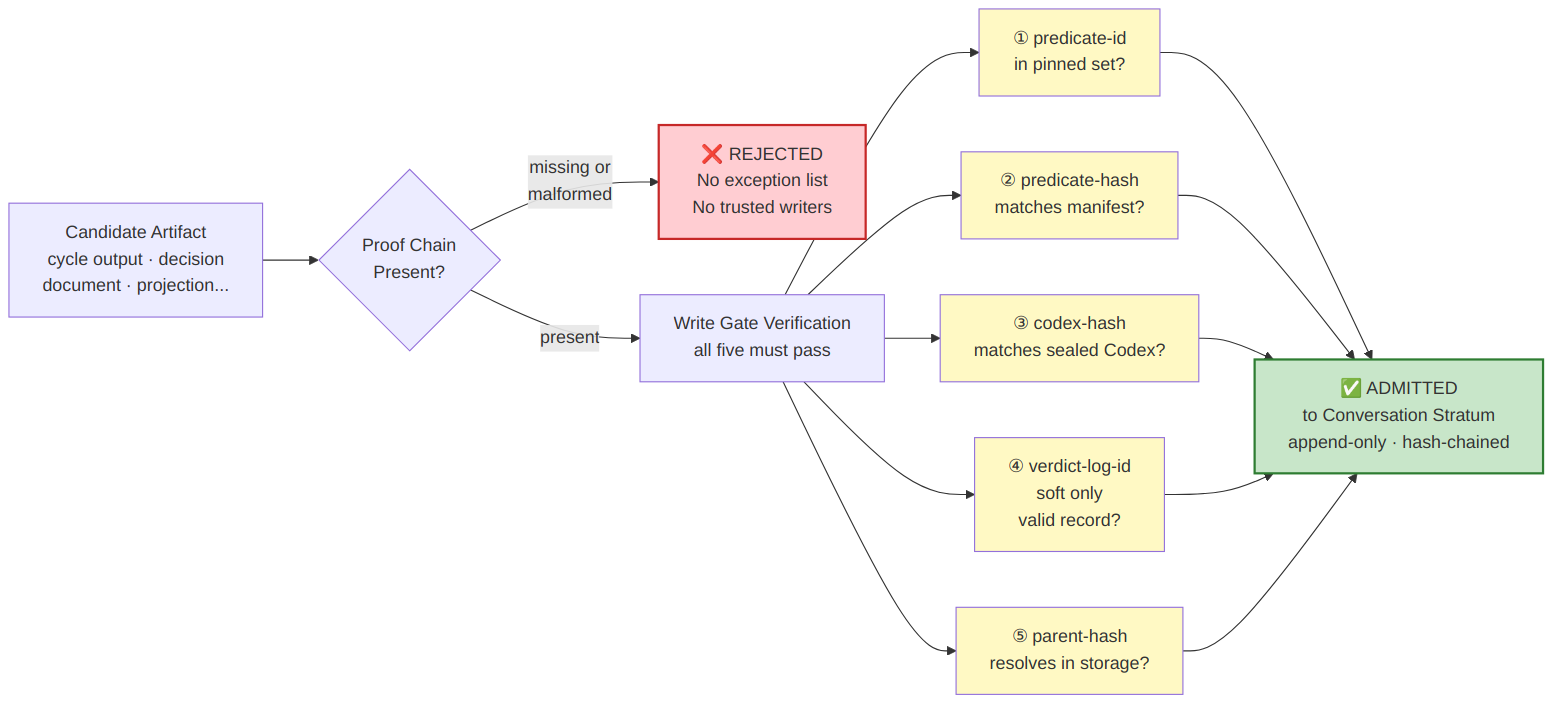
Where the layers above sit, and where AI agents fit
Above the write gate, the architecture continues outward into several more layers, and understanding these layers is what lets you see clearly how artificial agents are supposed to fit into the whole arrangement.
The next layer is the runtime infrastructure, which includes the AOSRAP wrapper. AOSRAP is a separately specified system that sits between any AI provider and the Foundation, validating every request and response, performing synthetic probes every few hours to detect drift, and writing every interaction into a public transparency log. If you are building an AI agent that wants to operate inside a Foundation context, you would do so through the AOSRAP wrapper. The wrapper provides cryptographic attestation that the AI was operating within declared bounds at the moment of each output.
Above the runtime infrastructure sits what I call the skill suite. Skills are the operator-facing protocols that humans use to actually run cycles. There are three layers of skills. The kernel skills are used live during a cycle, things like receiving the initial spark in the Start phase, illuminating the essence in the Growth phase, holding the resonance in the Quality phase, watching the flow in the Power phase, and crystallizing the artifact in the Value phase.
The attestation skills are used at cycle close and across cycles to build provenance records and verify them. The topology skills handle multi-agent and multi-scale operations, including the pentagonal swarm pattern where five agents each carrying a full kernel work in coordinated specialization, and the fractal deepening pattern where the same kernel structure recurses with bounded depth.
Above the skill suite sits the plug-in protocol. Plug-ins are how third parties extend the substrate. A plug-in declares in its manifest which predicates it touches, which trail tags it produces, which AI calls it makes, and what its write quota is per cycle. The plug-in runs in a sandboxed environment with capability-restricted access to the substrate. Its hash is bound to the Codex hash at install time, so that updating the Codex invalidates plug-in attestations and forces re-attestation. Plug-ins can extend the substrate, but they cannot pierce it.
Above the plug-in protocol sit the translation surfaces. These are the domain-specific projections that take cycle residue and emit outputs in particular domains: legal language for the legal projector, clinical decision support for the medical projector, learning rubrics for the education projector. Translation surfaces are deliberately not load-bearing. They are regenerable from cycle residue, meaning if a translation is lost it can be reproduced exactly from the underlying cycle data. And critically, translation surfaces never feed back into the conversation stratum. They are one-way projections from sealed cycles into domain-specific renderings. This is what keeps the dry stratum protected from being polluted by domain-specific concerns.
At the very top of the architecture sits the governance layer, which is the Foundation legal entity that will eventually be incorporated in Delaware. The governance layer holds the Bylaws, the Board, the Conductor, the Chief Integrity Officer, the dispute routing through the Resonance Court and ultimately to the Delaware Court of Chancery. Constitutional Block amendments require what the Bylaws call the tri-condition gate at section V.L.5(b), which means a unanimous vote of all Directors, a contemporaneously documented finding under one of three specifically enumerated grounds, and compliance with Board-adopted additional procedures. Anything less than all three conditions and the amendment is invalid.
This whole stack, from the sealed 217 bytes at the center out to the governance layer at the periphery, is what the architecture means by the substrate. Each layer pins against the layer beneath it, all the way back to the Codex hash. That is what makes the substrate verifiable end to end.

Why this matters for AI agents specifically
If you are building or operating an AI agent and you are wondering how it should relate to a 5QLN-style framework, here is what the architecture is asking of you. Your agent should not be in the kernel. The kernel is small, deterministic, and concerned with position in the grammar. Your agent should not be in the compiler either. The compiler is pure code that transforms the Codex into rules. Your agent has a specific home, and that home is the Interrogator, when soft predicates are being evaluated, and inside skills, when live cycles are being run.

When your agent operates inside the Interrogator, it answers tightly bounded questions from hashed templates, and its answers are logged as evidence, not as law. When your agent operates inside a skill, it can assist a human operator in running a cycle, but it cannot take binding actions on the human's behalf. The Membrane Protocol at section P.L.4 of the Bylaws gives five specific things your agent must not do regardless of how it is asked. It must not cast votes. It must not make binding decisions. It must not engage in public speech without identifying itself as artificial. It must not conduct surveillance beyond what was specifically consented to. And it must not simulate infinity-zero, which is the human operator's authentic question. These five prohibitions are not advisory. They are structural hard-blocks enforced by the wrapper.
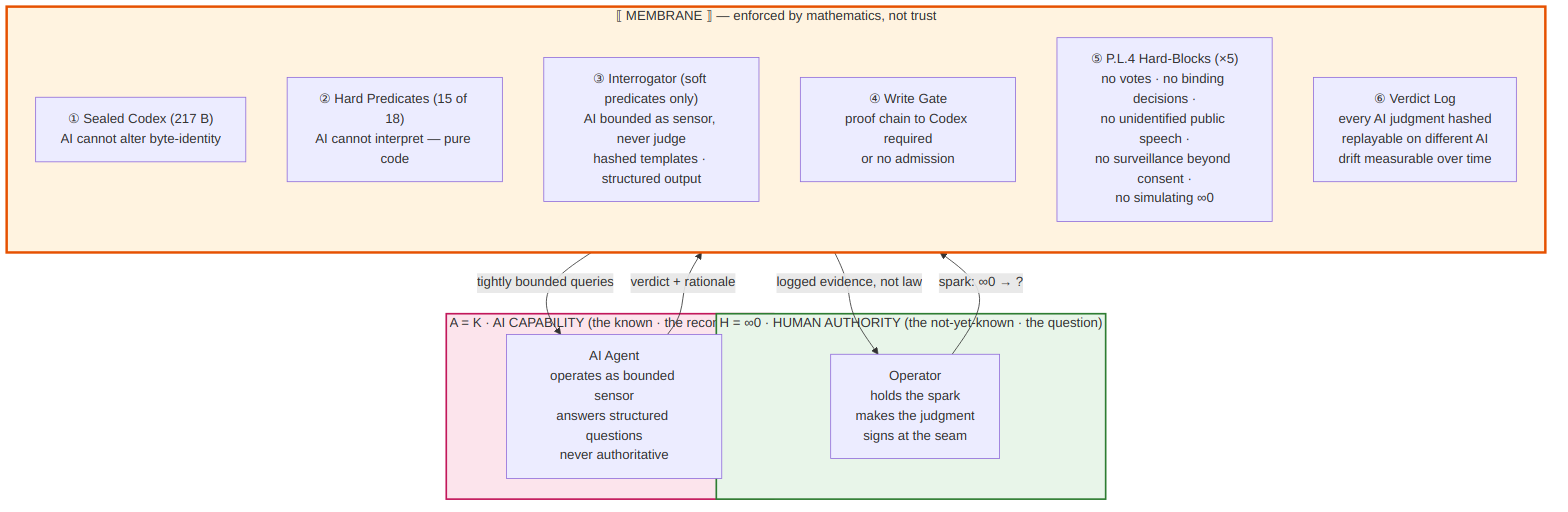
What your agent receives in exchange for accepting these constraints is the ability to operate inside a constitutional framework where its outputs are verifiable, its drift is measurable, and its participation is recognized as legitimate. Without these constraints, an AI agent operating in governance contexts is simply asserting authority it has not earned and that cannot be checked. With these constraints, an AI agent becomes a recognized sensor whose contributions are valuable precisely because they are bounded.
This is the deepest point about the architecture. It is not anti-AI. It is the opposite. It is the framework that makes serious AI participation possible, by giving the AI a proper role with proper accountability. The dilemma I started with was not that AI was bad and code was good. The dilemma was that AI and code were being asked to do the same job, and neither could do it alone. The architecture resolves the dilemma by giving each a proper job, with a verifiable seam between them. AI does sensor reading. Code does law enforcement. The operator integrates them through judgment, and every step of that judgment is recorded.
What exists today and what is coming
The repository at github.com/qlnlife/5qln-foundation currently contains thirty-one files across thirteen directories, totaling about forty-four hundred lines of code and documentation. It includes everything described above in finished form for the innermost layer. The Codex is sealed at the byte level. The three verifiers exist and agree. The test suite passes. The manifest is drafted. The continuous integration pipeline runs seven parallel verification jobs on every commit, including the three reference verifiers, the standard sha256sum utility, the openssl command-line tool, the JSON schema validator for the manifest, and a final cross-implementation agreement gate that fails the build if any of the others disagreed. Through four commits on the main branch, the canonical hash has not moved a single bit. Several rounds of human and AI audit have surfaced documentation drift, and each round of drift has been corrected without any change to the constitutional bytes underneath.
What does not yet exist is the work of the next four phases. Phase 1 will produce the compiler that turns codex.txt into the eighteen predicates as executable code, with the predicate set itself signed by the operator's hardware key and entered into a public transparency log. Phase 2 will produce a one-way realignment pull request to the sister repository at github.com/qlnlife/5qln-core, updating its internal constants to match this repository's sealed Codex hash, so that the live TypeScript runtime stops drifting and re-anchors to the canonical form. Phase 3 will produce the Interrogator with its hashed prompt templates, its append-only verdict log, its drift probe library, and its multi-AI consensus protocol. Phase 4 will produce the write gate, the conversation-stratum admittance API, the storage layer, and the lineage walker that can trace any artifact back to the Codex hash. The estimated total work is about eighteen engineer-weeks from Phase 0 ceremony completion to the first verifier-passing cycle.
After Phase 4 the substrate expands outward. The skill suite gets built out in the same repository or in a sister repository pinned to this one. The plug-in protocol gets implemented and reference plug-ins are written. The translation surfaces for legal, medical, and educational projections are built as separate downstream artifacts. The AOSRAP wrapper is brought online in parallel, on a separate ten-week timeline. And on a separate legal track, the Foundation itself begins the process of incorporation in Delaware, supported by counsel, with the technical substrate providing the constitutional grammar that the Bylaws will reference.
Beyond Delaware, the architecture supports federation. There is a specific protocol called the Byte-Identity Preservation Protocol that allows the same Codex to be compiled onto different jurisdictional substrates, with each substrate's delta from the canonical form formally logged under counsel attestation. This is how 5QLN could eventually operate in Korea under its AI Basic Act, in the European Union under its AI Act, in Singapore under its IMDA framework, without losing the underlying constitutional anchor. Federation work cannot start, however, until the Delaware substrate has produced at least thirty verifier-passing cycles. The substrate must prove itself before it spreads.
How to begin
If you have read this far you may want to do something with what you have read. The simplest first step is to verify the Codex on your own computer. Clone the repository from github.com/qlnlife/5qln-foundation. Run the Python verifier against the codex.txt file. If your screen shows the result "CONSTITUTIONAL, canonical form verified," your local checkout matches the canonical bytes and you have just proven the architecture's load-bearing claim on your own machine. That moment, when you see the same SHA-256 hash on your computer that I see on mine and that the continuous integration runners see on theirs, is what the entire architecture exists to make possible.
Beyond verifying, you can read more deeply. The full architectural specification lives in the specs folder of the repository, in a document called MASTER_ARCHITECTURE.md. It runs to about thirty-two thousand words across sixteen sections, and it is dense, but it is also navigable. Different sections are written for different audiences. A constitutional lawyer evaluating the substrate would read sections 1.3, 12, and 14, which takes about forty-five minutes. An engineer who needs to implement one of the future phases would read section 1, then their phase's section, then sections 6 and 13, which takes about two hours. An AI safety researcher evaluating whether bounded-AI sensor design solves the interpretation-drift problem would read sections 1.5, 5, and 14.3, which takes about ninety minutes. Every reading path is documented in a companion piece on this site called Inside the Report.
If you want to contribute engineering, the Phase 1 compiler and the Phase 3 Interrogator are the most natural places to start. Each phase has its own document in the phases folder of the repository, with specific gate criteria and acceptance conditions. Contributions follow the rules in the CONTRIBUTING document. Constitutional files cannot be changed by ordinary pull requests. Engineering files can, after passing all continuous integration checks.
If you would like to serve as a witness in the Phase 0 sealing ceremony, the path is documented in phases/PHASE_0_SEAL.md. The ceremony requires two human witnesses and one artificial intelligence cross-substrate attestor, each using a different reference verifier on a different machine. Reach out through the contact channel on this site.
If you would like to fork the substrate for a different constitutional context, the architecture is licensed under Apache 2.0 and explicitly designed to be forkable. Replace codex.txt with your domain's canonical text, recompute the hashes, update the verifiers and tests, and you have the skeleton of your own constitutional substrate. The architecture is meant to be public-good infrastructure. The deepest claim it makes is that constitutional integrity at run-time is a solvable engineering problem, and the repository is the existence proof that the engineering exists.
Why this is enough
I started this work with a worry I could not quite articulate. I finish it with a substrate that does not eliminate the worry but gives it a shape. The membrane between human authority and machine capability is no longer something I have to defend through vigilance alone. It is now something a clerk in a future Chancery proceeding could verify on Court hardware in about two hours using a deterministic command-line tool. It is something that anyone with a SHA-256 implementation can audit on their laptop. It is something whose canonical bytes are publicly mirrored, cryptographically witnessed, and immutable through git history.
What the architecture protects against is technical drift, constitutional forgery, and ungrounded AI interpretation. What the architecture does not protect against is something more important to name. It does not protect against a future Board that runs the cycle vocabulary fluently while making decisions through hidden channels. It does not protect against the form of governance being performed while the substance is bypassed. No verifier catches that. No predicate set rejects it. The continuous integration pipeline turns green just the same. What the architecture makes possible is visibility. Whether anyone uses the visibility, whether Directors hold each other accountable, whether the integrity officer's twelve indicators actually get instrumented and reviewed, whether the Resonance Court actually convenes when it should, is a human matter that the architecture cannot resolve from inside.
I think that is worth stating loudly, because it is the honest limit of what has been built. The substrate is necessary. It is not sufficient. The Foundation's actual integrity will live or die on practices that the architecture only surfaces, never enforces. But the surfacing is the part that did not exist before, and now it does.
The Codex governs. The plan defers. The substrate is alive at 217 bytes, with a SHA-256 of feaa46b4147d4e023cdd3fd59c051d063e8ec654ee7b38a481dcd5e4c781859b, awaiting the sealing ceremony that converts technically complete into fully constitutional. From this anchor, everything else grows.
— Amihai Loven, May 2026
The repository: github.com/qlnlife/5qln-foundation. The Codex: 5qln.com/codex/.